
View
종종 필요할 때가 있어서 데이터분석과 머신러닝을 공부했었는데,
예측모델을 만들 때 도대체 어떤 모델을 사용해야할지... 감이 안올 때가 많았습니다.
그러던 중에 pycaret이라는 매우 유용한 라이브러리 발견!
이 라이브러리는 코드 한줄만으로 여러 모델의 정확도를 한번에 알 수 있습니다.
튜닝, 시각화 등의 기능도 제공하기에 입문자가 여러가지 시도해보기 좋을 것 같습니다.
사용법도 익힐 겸, pycaret으로 간단히 타이타닉 생존자 예측 프로젝트를 진행해봤습니다.
1. 설치하기
pip install pycaret가끔 설치 중에 멈출 때가 있었는데 그땐 엔터를 여러번 눌러보고,
에러가 뜨면 프롬프트창을 관리자 권한으로 실행하고 다시 받아보세요.
2. 데이터 전처리
타이타닉 데이터를 전처리 없이 그대로 입력해도 상관없지만,
조금이라도 전처리를 하는 편이 좀 더 의미있는 결과가 나오지 않을까 싶습니다.
그래서 간단하게나마 전처리도 진행했습니다. pandas를 사용합니다.
towardsdatascience.com/classification-with-pycaret-a-better-machine-learning-library-cff07a10a28c
Classification with PyCaret: A better machine learning library
Solving classification tasks with PyCaret — it’s easier than you think.
towardsdatascience.com
이 글을 읽고 pycaret을 처음 알게 됐는데, 여기에 쓰여진 전처리 코드를 사용했습니다.
원글에선 매우 간단히 설명하고 넘어간 부분이지만... 공부 겸 코드를 파트별로 나눠서 써봤습니다.
타이타닉 데이터셋의 기본 형태
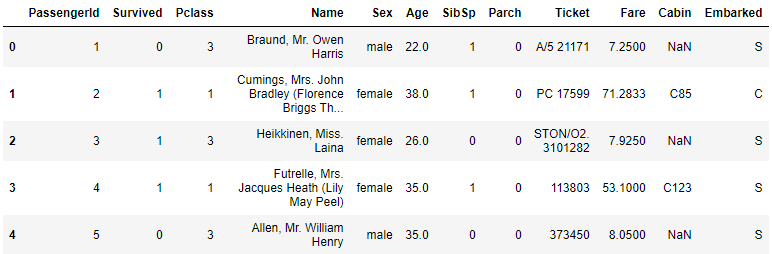
2-1. 필요없는 속성 지우기
Ticket과 PassengerId 컬럼은 삭제합니다.
df.drop(['Ticket', 'PassengerId'], axis=1, inplace=True)
df.columns #확인
2-2. 성별 속성의 값을 0과 1로 바꾸기
gender_mapper = {'male': 0, 'female': 1}
df['Sex'].replace(gender_mapper, inplace=True)
df['Sex'].head() #확인
2-3. 승객 이름에 특별한 정보가 붙는지 확인
예시로 doctor, Mr, Miss 등의 호칭이 붙는 경우, 별도로 새로운 속성에 저장합니다.
df['Title'] = df['Name'].apply(lambda x: x.split(',')[1].strip().split(' ')[0])
# 명칭이 존재하는 경우 0, 아닐 경우 1
df['Title'] = [0 if x in ['Mr.', 'Miss.', 'Mrs.'] else 1 for x in df['Title']]
df = df.rename(columns={'Title': 'Title_Unusual'})
df.drop('Name', axis=1, inplace=True)
df['Title_Unusual'].head() #확인
2-4. 선실 정보의 유무를 저장
선실 정보가 있는 경우는 1, nan일 경우는 0으로 저장합니다.
df['Cabin_Known'] = [0 if str(x) == 'nan' else 1 for x in df['Cabin']]
df.drop('Cabin', axis=1, inplace=True)
df['Cabin_Known'].head() #확인
2-5. 승선지에 관한 dummy 변수들을 생성
승선지는 총 3종류이기에, 이 정보를 저장하기 위해 더미변수를 생성합니다.
emb_dummies = pd.get_dummies(df['Embarked'], drop_first=True, prefix='Embarked')
df = pd.concat([df, emb_dummies], axis=1)
df.drop('Embarked', axis=1, inplace=True)
df.head() #확인
2-6. 비어있는 나이는 평균값으로 채우기
df['Age'] = df['Age'].fillna(int(df['Age'].mean()))
df['Age'].head() #확인
이렇게 전처리가 끝났습니다.
전처리 최종 결과

3. pycaret 모델링
우선 setup 메소드를 작성합니다.
from pycaret.classification import *
clf = setup(df, target='Survived', session_id=42)가장 최소한으로 작성했을 때, 데이터 타입은 자동적으로 계산됩니다.
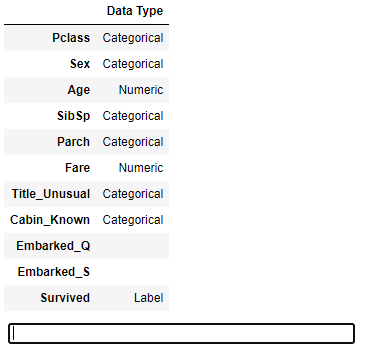
코드를 실행하면 분류된 데이터 타입을 표시해주는데,
이상이 없다면 Enter를 눌려주면 다음 단계가 진행됩니다.
혹시 범주형 변수와 수치 변수를 직접 구분하고 싶다면, setup을 작성할 때
categorical_features와 numeric_features에 리스트 형태로 속성 이름을 써주면 됩니다.
#Data Type 직접 정의하기
clf = setup(df, target='Survived', session_id=42,
categorical_features = ['Embarked_Q'],
numeric_features = [])
입력 안한 속성은 자동으로 분류됩니다.
단순한 데이터셋의 경우는 그냥 자동으로 놔두는게 나은 것 같습니다.
4. 모델링 결과
setup() 실행 후, 단 한줄만 써주면 됩니다. 실행시 조금 시간이 걸립니다.
compare_models()
각 모델별 정확도를 코드 한줄로 한번에 확인할 수 있습니다!
CatBoost 모델이 제일 정확도가 높게 나왔네요.
CatBoost 모델을 생성해봅니다.
model_cat = create_model('catboost')
pycaret은 모델 튜닝 기능도 제공합니다.
tuned_cat = tune_model(model_cat)
하지만 튜닝을 한다고 반드시 성능이 좋아지는건 아니기에,
꼭 필요한 사항은 아닌 것 같습니다.
시각화랑 최종예측은 다음 글에 이어서 쓰겠습니다.
'Data Science' 카테고리의 다른 글
| [pandas] 옵션 수정, 생략 없이 출력하기 (0) | 2021.01.20 |
|---|---|
| [pandas] csv와 json이 혼합된 파일 형식 (0) | 2021.01.04 |
| pycaret으로 타이타닉 생존자 예측 (2) (1) | 2020.12.24 |
